

昨年から今年に入り、マサチューセッツ工科大学とGoogleなどの共著で、SageDBなどの機械学習によるデータベース最適化の論文が発表されています[1][2]。現時点では研究レベルの論文ではありますが、将来のデータベース在り方について色々な示唆に富んでいる論文です。
今回は、この論文の主要コンセプトである「学習によるカスタマイズ」に関連する話題にふれ、今後のデータベース像について考えてみます。
データベース最適化の背景
データベース最適化の研究については長い歴史がありますが[1][5]、SageDBの論文[1]では、(データベースを含む)既存のデータ処理一般の最適化(カスタマイズ)手法を以下の3種類に分類しています。
設定によるカスタマイズ (Customization through Configuration)
まずは、最も馴染み深いであろう、データーベースのコンフィグ設定やシステム設定変更による最適化です。具体的な例としては、各データベースのページサイズ、バッファプールサイズの調整などが該当します。広義的な意味では、インデックスやマテリアライズド・ビューの作成も含まれますが、基本的には静的なカスタマイズ手法と位置付けられています。
設定によるカスタマイズについては、データベースへのワークロードやデータ特性から設定値を自動的に最適化する先行研究が数多くあり、近年では機械学習をデータベースに応用した汎用的な最適化の研究もあります[4]。
アルゴリズム選択によるカスタマイズ (Customization through Algorithm Picking)
前述の静的な「設定によるカスタマイズ」に対して、動的な実行戦略の選択によるクエリー最適化の手法で、データベースの主要な研究の分野として長い歴史があります[1][5]。具体的な例としては、クエリー最適化は、オプティマイザにより最適な実行順序(例:述語プッシュダウン、結合順序など)を決定し、利用可能な一連のアルゴリズムから最良の実装を選択(例:ネステッドループ結合、ハッシュ結合など)するものです。
この最適化手法は、実行前にそのコストを推定するため、コストに基づく最適化(cost-based optimaization)とも呼ばれ、コスト推定には統計的な手法の基づくものが広く実装されています[5]。
自己設計によるカスタマイズ (Customization through Self-Design)
自己設計システムとは、システム内の選択可能なプリミティブから、データベースのワークロードとハードウェアに最適な組み合わせを自動的に生成するという概念のものです [3]。選択可能なプリミティグには、ハードウェアだけではなく、分散システムのパーティショニング方法(例: ハッシュ分割、レンジ分割)やデータアクセス方法(例: スキャン、ソート済検索など)などのソフトウェア(アルゴリズム)も含まれます [3]。
この最適化手法には、学習コストモデルを用いた最適化が用いられており、新しい組み合わせが未知のアルゴリズムやデータ構造を生み出すことで、パフォーマンスを大幅に向上させる可能性もあるとされ[3]、今回のSageDB[1]の論文と合わせて興味深い概念です。
SageDBとは?
現代のデータベース(原文:データ処理システム)は、多種多様なスキーマ、データ型、およびデータ分散を処理できるように汎用的に設計されています。その反面、その最適化については、前述の「アルゴリズム選択によるカスタマイズ」(=コストに基づく最適化)に基づくものが多く、特定のワークロードやデータ特性に対して適応できない可能性があります[1][2]。
SageDBでは「学習によるカスタマイズ」と名付けられた、既存のデータベース(原文:データ処理システム)のアルゴリズムとデータ構造に(機械学習の)モデルを深く埋め込むことによる最適化手法を提案しています。
学習によるカスタマイズ (Customization through Learning) とは?
今回のSageDBの論文に先立ち、筆者らは、既存のデータ構造およびアルゴリズム、具体的にはデータベースのインデックス操作にB-Treeを深層学習モデルに置換する先行研究を発表しています [2]。
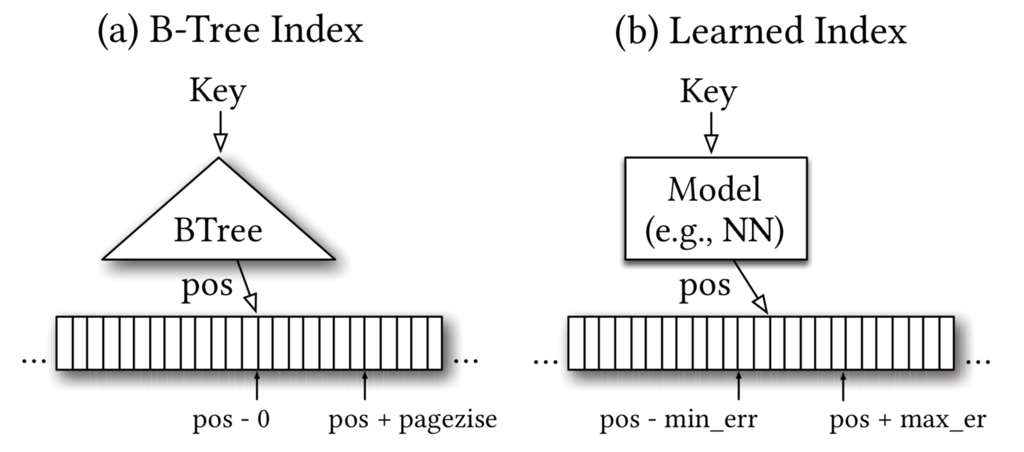
B-Treeはデータ構造的な観点からは木(Tree)構造ですが、機械学習的な観点からは決定木(Decision Tree)です。この先行論文は、B-Treeを線形回帰やニューラルネットを含む他の機械学習モデルへ置き換え可能なことを提示しています。
前述の「自己設計によるカスタマイズ」との比較すると、選択可能なプリミティブを選択するのではなく、「学習によるカスタマイズ」では、そのプリミティブとなるアルゴリズムとデータ構造に(機械学習の)深く埋め込み、従来のアルゴリズムとデータ構造自信を置き換える手法となります。
SageDBの目指す世界
SageDBは、機械学習モデルが適用されたプリミティブをを合成することによりデータベースシステムを構築する、新しい世界をデータベースのの世界を提案しています。
今回の研究範囲でのモデル適用は、インデックス構造などの限定されたプリミティブのみに留まっていますが、概念的にはすべてのアルゴリズムとデータ構造に(機械学習の)モデルを埋め込み、それらを合成することにより、頭脳化されたデータベースを構築する壮大なビジョンを提示しています。
また、「学習によるカスタマイズ」の将来像としては、その適用範囲はデータベースにとどまらず、GPUやTPUを活用することで、次世代のビッグデータ処理ツールが生まれることも示唆しており、なかなか興味深い概念といえます。
最後に - アルゴリズムか学習か?
機械学習は、Arthur Samuelによる「明示的にプログラムしなくても学習する能力をコンピュータに与える研究分野」との定義があります[6][7][8]
。機械学習は、2010年代に画像認識[9]や音声認識[10]の分野では既に大きな成果を上げており、既存のモデルやアルゴリズムが駆逐されるような状況が発生しています[11]。
今回のSageDBの論文が示唆するように、データベースの世界でも既存の明示的なプログラム(=アルゴリズム)、一歩踏み込んで表現を変えると、既存のモノシリックなデータベースが、機械学習により駆逐される将来はありうるのでしょうか?
いずれにしろ、このような機械学習によるパラダイムシフトは興味深い話題[12]ですので、個人的にも色々考えてみたいと思っています。
参考文献
- [1] Kraska, Tim, et al. "Sagedb: A learned database system." (2019).
- [2] Kraska, Tim, et al. "The case for learned index structures." Proceedings of the 2018 International Conference on Management of Data. ACM, 2018.
- [3] Idreos, Stratos, et al. "The data calculator: Data structure design and cost synthesis from first principles and learned cost models." Proceedings of the 2018 International Conference on Management of Data. ACM, 2018.
- [4] Van Aken, Dana, et al. "Automatic database management system tuning through large-scale machine learning." Proceedings of the 2017 ACM International Conference on Management of Data. ACM, 2017.
- [5] 増永 良文, リレーショナルデータベース入門―データモデル・SQL・管理システム・NoSQL (Information & Computing)サイエンス社, 2017
- [6] 機械学習 - Wikipedia
- [7] Samuel, Arthur L. "Some Studies in Machine Learning Using the Game of Checkers. II—Recent Progress." Computer Games I. Springer, New York, NY, 1988. 366-400.
- [8] Source of Arthur Samuel's definition of machine learning
- [9] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet classification with deep convolutional neural networks." Advances in neural information processing systems. 2012.
- [10] Seide, Frank, Gang Li, and Dong Yu. "Conversational speech transcription using context-dependent deep neural networks." Twelfth annual conference of the international speech communication association. 2011.
- [11] Ian Goodfellow (著), Yoshua Bengio (著), Aaron Courville (著), 岩澤 有祐 (監修), 鈴木 雅大 (監修), 中山 浩太郎 (監修), 松尾 豊 (監修), 深層学習, KADOKAWA, 2018
- [12] Preferred Research - プログラミング教育推進月間の教材について