
と設計連続体(Design Continuums)の概念について")
自己設計システムとは、システム内の選択可能なプリミティブから、データベースのワークロードとハードウェアに最適な組み合わせを自動的に生成するという概念のものです[1]。今回は、この自己設計システムのコンセプトの著者の、キーバリューストアを題材とした直近の論文を紹介してみます[2]。
自己設計によるカスタマイズ (Customization through Self-Design)とは?
自己設計(Self-Design)は中世の原子論的に、基礎となる設計要素を組み合わせ、最適な組み合わせとなるシステムを構成する概念のものです。選択可能なプリミティグには、ハードウェアだけではなく、分散システムのパーティショニング方法(例: ハッシュ分割、レンジ分割)やデータアクセス方法(例: スキャン、ソート済検索など)などのソフトウェア(アルゴリズム)も含まれます [3]。
自己設計による最適化手法には、学習コストモデルを用いた最適化や機械学習が用いられ、新しい組み合わせが未知のアルゴリズムやデータ構造を生み出すことで、パフォーマンスを大幅に向上させる可能性があります[1][3]。本論文では、具体的な評価対象システムとしてキーバリューストアを題材に、自己設計(Self-Design)における手法を提案しています。
キーバリューストアとは?
キーバリューストアは、キーと値のペアを格納するデータ構造を実装したものです。キーバリューストアは、ソーシャルメディアのグラフ処理、アプリケーションデータのキャッシング、NoSQLストレージ、オンライントランザクション処理などの、多種多様なアプリケーションの基盤として活用されています[2]。
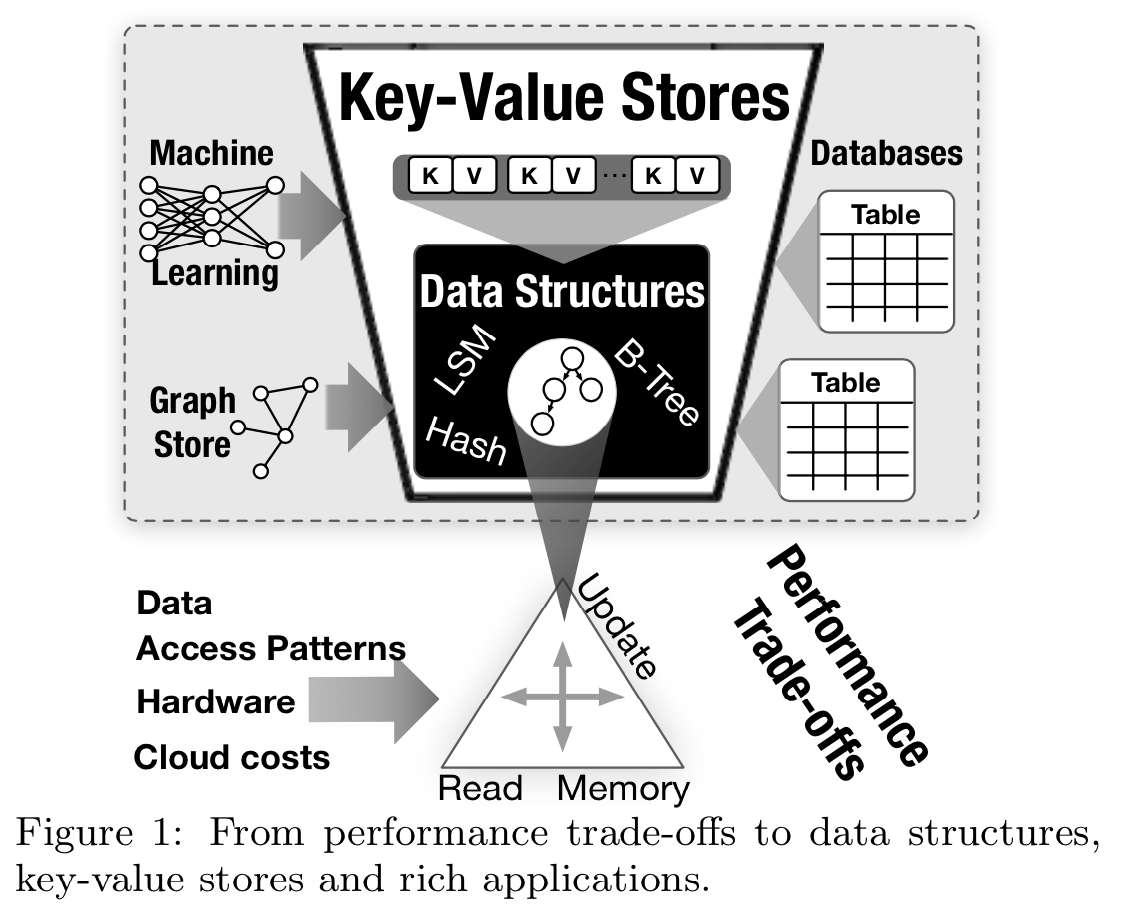
また、近年のリレーショナルデータベースであるGoogleのSpannerや、RockDBをMySQLのバックエンドストレージとしたMyRocks、FoundationDBをバックエンドストレージとしたデータウェアハウスのはSnowflakeなども、バックエンドにキーバリューストアが採用されています
[2][5]。
主要なKey-Valueデータ構造
キーバリューストアのデータ構造については、読み取り・書き込み・メモリ消費量には常にトレードオフが存在し、この3つ全てを最適とするデータ構造は存在しません[2]。結論としては各目的に応じたデータ構造が必要となるのですが、現時点で代表的なデータ構造として、B+Tree、LSMツリーなどが存在しています。
B+Tree
B+Treeは、RDBMSやファイルシステムでも採用されている主要なツリー構造で、合理的なメモリ消費量で読み取りと書き込み性能のバランスに優れ、現在はOracleの製品であるBerkeleyDBや、近年でもMongoDBの標準ストレージエンジンとなったWiredTiger、FoundationDBなどのキーバリューストアに採用されています。
LSMツリー
LSMツリー(Logs-structured merge-tree)は、高速な書き込みと読み取り性能を共存させるデータ構造で、GoogleのLevelDBやBigTable、FacebookのRocksDB、Apache CassandraやHBase、さらにはMySQLやSQLiteなどのRDBMSの主なキー管理などにも採用されています。ただし、B+ツリー構造より書き込み性能は優れますが、読み込み性能は悪化する場合があります。
その他 (LSHテーブル、ハイブリッドな構成など)
近年はRiakのBitCaskやSpotifyのSparkeyに用いられているLSHテーブル(Log-Structured Hash-table)などの新しい構造もあります。また、アプリケーションに適切なパフォーマンスを提供するため、複数のデータ構造を排他的に提供する場合もあります。例えば、MongoDBのWireTigerでは、B+TreeとLSMツリー実装を排他的に個別にサポートしており、RocksDBでは部分的にハッシュテーブル構造を取り入れて最適化しています。
多くの最新のキーバリューストアは、相互に排他的なスワップ可能なデータレイアウト設計のセットで構成され、多様なパフォーマンス特性を提供します。たとえば、WiredTigerはBツリーとLSMツリーの実装を個別にサポートして読み取りまたは書き込みをそれぞれ最適化しますが、RocksDBファイルはソートされた文字列レイアウトまたはハッシュテーブルレイアウトをサポートして、範囲の読み取りまたはポイントをさらに最適化しますそれぞれ読み取ります。
自己設計(Self-Design)の目的
自己設計(Self-Design)の長期的な研究課題は、例えば前述のキーバリューストアの場合、対象の問題に最適なデータ構造を、簡単または自動的に選択できるかが重要な課題となります。自己設計は、対象となるドメイン知識となる原則を導き出すことを目的としており、今回の論文では、自己設計を実現するものとして、連続体(Design Continuums)の概念を提唱しています。
連続体(Design Continuums)の概念
蘭族隊の、全体の集合となる設計空間(Design Space)には、現在認識できている設計要素(Design Primitives)となるデータ構造から構成されています。今回の論文の自己設計(Self-Design)の手法は、この設計要素の最小セットの組み合わせ、つまりは設計空間(Design Space)の部分集合として導出するものです。この論文の、連続体(Design Continuums)は、設計空間(Design Space)から導出される部分集合を、性能を軸とする超平面(Hyperplane)に連続(隣接)して射影しうる概念的な手法を提唱しています。
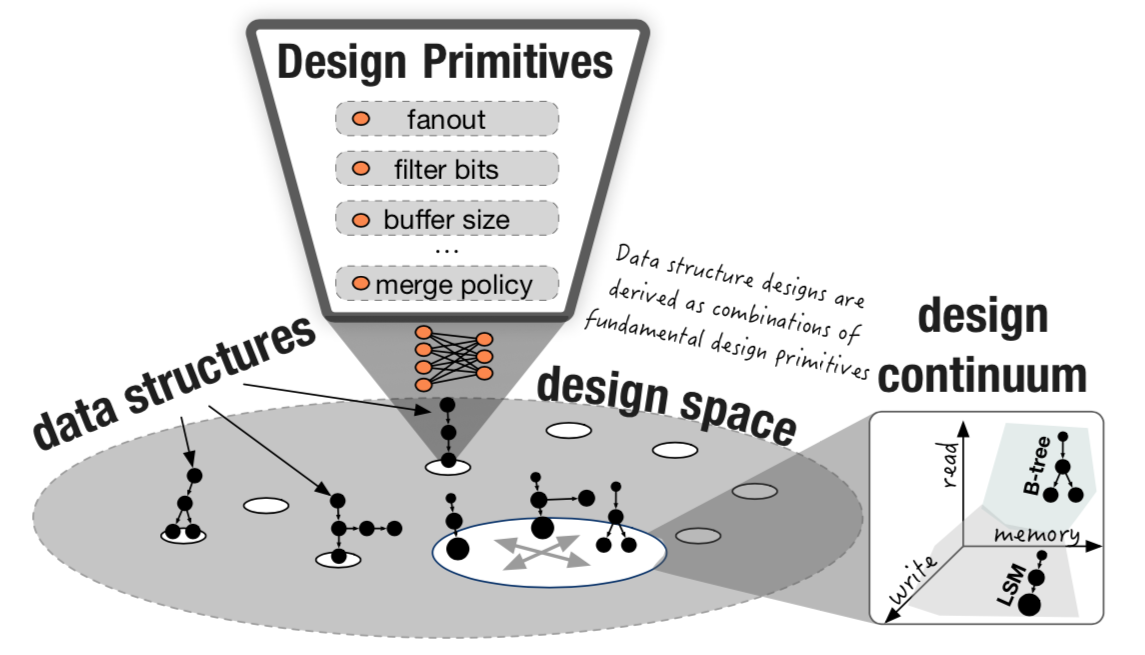
設計空間(Design Space)にある各設計は基本設計要素の最小セットの組み合わせから導出され、この設計空間から設計連続体(Design Continuums)に導出されたサブセットは性能など計測可能なものと定義されています。設計連続体(Design Continuums)は概念的には、上の抽象図に示すように連続体(Design Continuums)に導出されたサブセットは、超平面(Hyperplane)に連続(隣接)して射影された性能平面として概念的に説明されています。
統合コストモデルの提案
設計連続体(Design Continuums)の概念の実例として、本論文ではキーバリューストアを題材とした自己設計型の統合コストモデルを提案しています。前述のキーバリューストアの現在の代表的なデータ構造であるB+TreeやLSMツリーなどを超平面に射影する連続体を提示しています。設計連続体には、主要な性能指標が環境変数(Environment Parameter)や設計パラメータ(Design Parameter)などの変数(Term)や、これら変数を組み合わせた導出した導出変数(Derived Term)から構成されるコストモデルとして定義されます。

本論文はキーバリューストアにおける更新(Update)などの各クエリーを、環境変数(Environment Parameter)や設計パラメータ(Design Parameter)および導出変数(Derived Term)を組み合わせて導出した、導出設計規則(Derived Design Rule)をキーバリューストアの一般コストモデルとして定義しています(上右表)。この導出設計規則(Derived Design Rule)は、キーバリューストアの各クエリーで発生するI/O操作の最悪のケースを示しています。
本論文は、自己設計(Self-Design)の方法論として、連続体(Design Continuums)を構築する手順を提案したモノです。連続体(Design Continuums)を構築するにあたり、選択できるデータ構造を環境変数(Environment Parameter)や設計パラメータ(Design Parameter)などに素因数分解し、それらの最小構成要素から導出変数(Derived Term)、最終的には問題を評価する導出設計規則(Derived Design Rule)を統合コストモデルとして定義することを提案しています。
最後に
近年は、Peloton[3]やSageDB[3][4]など、機械学習をデータベースに適用した研究が活発化しています。Peloton[3]は典型的なARMAモデルのような予測による最適化ではなく、複数のグループにクエリーを分割した機械学習(RNN)の最適化を提案しています。SageDB[3]は、既存のデータ処理システムのアルゴリズムとデータ構造に(機械学習の)モデルそのものを埋め込むことによる最適化手法を提案しています。
本論文では、比較的単純なキーバリューストアを題材として連続体(Design Continuums)の概念を実証していますが、最終的に本論文が目指すものは、設計継続の連続体(Design Continuums)の構築を(半)自動化し、グラフや空間データより広範なデータ構造設計への応用が最終的な目標とされています。その最終的な目標の実現のためには、本論文においても、今後の展望としては連続体(Design Continuums)への機械学習の適用が示唆されています。
また、本論文が目指すような世界の実現には、典型的な密結合されたモノリシックなデータベース構造では、クラウドコンピューティングで求められる性能やスケールアウト性に課題があり[7][8]、近年のクラウドコンピューティングでは分散を前提とした疎結合および最適化された密結合なデータベースが席巻してきています[7][8][9]。
データベースの運用および最適化については、従来までは職人的な経験や知識が求められてきましたが、商用データベースの世界では機械学習の導入によりDBA(データベース管理者)に求められる人物像も急速に変化してきています[6]。また、従来の密結合であったデータベース設計においても適切な疎結合性を導入するなどアーキテクチャの刷新も求められており、データベース分野における求められる設計および人材についても、これから大きな転換期を迎えるのかもしれません。
参考文献
- [1] Idreos, Stratos, et al. "The data calculator: Data structure design and cost synthesis from first principles and learned cost models." Proceedings of the 2018 International Conference on Management of Data. ACM, 2018.
- [2] Idreos, Stratos, et al. "Design Continuums and the Path Toward Self-Designing Key-Value Stores that Know and Learn." CIDR. 2019.
- [3] Pavlo, Andrew, et al. "Self-Driving Database Management Systems." CIDR. Vol. 4. 2017.
- [4] Kraska, Tim, et al. "Sagedb: A learned database system." (2019).
- [5] 学習によるデータベース最適化について – SAGEDB: A LEARNED DATABASE SYSTEM
- [6] キーワードは「自律化」「自動化」――、Oracle Open World 2017で披露された“明日を実現”する技術 - クラウド Watch
- [7] Verbitski, Alexandre, et al. "Amazon aurora: Design considerations for high throughput cloud-native relational databases." Proceedings of the 2017 ACM International Conference on Management of Data. 2017.
- [8] Chrysafis, Christos, et al. "Foundationdb record layer: A multi-tenant structured datastore." Proceedings of the 2019 International Conference on Management of Data. 2019.
- [9] Bacon, David F., et al. "Spanner: Becoming a sql system." Proceedings of the 2017 ACM International Conference on Management of Data. 2017.
これらのコストモデルは、各操作タイプに対して発行されるI / Oの最悪ケース数を測定します。これは、通常、I / Oがメモリに収まらないほど大量のデータを格納するキーバリューストアのパフォーマンスボトルネックであるためです。 .2たとえば、ポイント読み取りのコストは、ホットレベルでの誤検知によるI / Oの予想数(psumの式、FPRの合計[25]で与えられる)をフラクショナルカスケードでは実行ごとに1つのI / Oを実行するため、コールドレベルで実行されます。別の例として、書き込みのコストは、アプリケーションの更新が各ホットレベル(最大を除く)で平均O(T / K)回コピーされ、最大ホットでO(T / Z)回コピーされることを観察することによって導き出されます。レベルと各コールドレベルで。これらのコストを追加し、単一の書き込みI / Oが元の実行から結果の実行にBエントリをコピーするため、ブロックサイズBで割ります。
4.特定の設計決定において、キーバリューストアは学習に依存する必要があることを示します。これは、それらを連続的に取り込むのが難しい(おそらく不可能な場合もある)ためです。
- We show that for certain design decisions key-value stores should still rely on learning as it is hard (per- haps even impossible) to capture them in a continuum.
連続体の定義。 これで、元の
連続体の行為の定義。 設計連続体は、以前は明確で一見基本的に異なるデータ構造設計を接続します。 構築プロセスでは、必ずしも数学的な意味で連続したノブが得られるとは限りません(ほとんどの設計ノブには整数値があります)。
ただし、設計の観点から、連続体は以前に接続されていない設計の間にサブスペースを開きます。 これらの個別の設計をきめ細かなステップで接続できます。これがまさに「設計連続体」と呼ばれるものです。 これが重要な理由は、1)これらのきめの細かいデザインオプションの組み合わせとして導出された、以前は知らなかったデザインを「見る」こと、および2) 中間状態。
平均操作コストθをモデル化することにより、ナビゲーションプロセスを形式化します。 係数は、ワークロード内のそれぞれの割合を表します)。
fewer design parameters
具体的には、(同じターゲット設計の)設計パラメータが少ないほど、抽象化がよりクリーンになり、最適な設計(後述)を自動的に見つけるアルゴリズムを簡単に見つけることができます。 2つの方法で設計パラメーターの数を最小化します。1)優れた設計に関する専門知識をカプセル化する決定論的設計ルールを追加すること、および2)複数の相互接続された設計決定を単一の設計パラメーターに集約すること
建設の概要 - Construction Summary
連続体の定義
連続体の行為定義。 設計連続体は、以前は明確で一見根本的に異なるデータ構造設計を接続します。 構築プロセスでは、必ずしも数学的な意味で連続したノブが得られるとは限りません(ほとんどの設計ノブには整数値があります)。
実験
設計連続体は、これらすべての設計をカプセル化する上部構造と考えることができます。
具体的には、(同じターゲット設計の)設計パラメータが少ないほど、抽象化がよりクリーンになり、最適な設計(後述)を自動的に見つけるアルゴリズムを簡単に見つけることができます。 2つの方法で設計パラメーターの数を最小化します。1)優れた設計に関する専門知識をカプセル化する決定論的設計ルールを追加すること、および2)複数の相互接続された設計決定を単一の設計パラメーターに集約すること。 たとえば、ブルームフィルターとフェンスポインターのメモリバジェットには、各レベルで一緒に使用する場合にのみ意味があるため、1つのパラメーターを使用しました。
関連
ワークロードに最適な設計を知ることで、オンザフライで適応できるシステムの機会が開かれます。クエリへのストレージの適応[38、4、11、46、40、27、37、60]を含むいくつかの形式で適応性が研究されてきましたが、新しい機会は通常、根本的に異なるデザインと見なされるものの間で変化しています。
たとえば、LSMツリーからBツリーへ。これにより、システムは多様なワークロードパターンのより大きな配列に適切に適応できます。設計連続体は、次の2つの理由により、このようなビジョンを少しだけ近づけます。1)(可能な設計のセットから)最適なデータ構造設計をすばやく計算できるようにする、2)可能な中間データ構造設計を知ることで「離れた」デザイン間の遷移ポイントとして使用されます(そうしないと、遷移するにはコストが高すぎます)
このような自己設計システムへの道には、(少なくとも)3つの課題があります。a)任意の2つの設計間で物理的に移行するアルゴリズムの設計、b)多様な設計を利用するために必要なコードを自動的に適合化、c)連続してカプセル化するのが困難なレイアウト決定を超える基本的なシステム設計ノブ。以下では、これらの研究課題について簡単に触れ、それらが解決される可能性が高いというヒントを示します。
トランジション
すべての適応研究と同様に、移行のコストを考慮する必要があります。 ここでの新しい課題は、根本的に異なる設計間での移行です
コード生成
カスタマイズされたストレージでは、最大のパフォーマンスを得るためにカスタマイズされたコードが必要です[4]。 連続体は、そのような経路に向けた手段を提供します。 連続した多様な設計を記述する統一モデルが存在するため、これは、可能な各設計の操作oの個々のアルゴリズムをインスタンス化できる各操作oの単一の一般化アルゴリズムを書くことができることを意味します。 たとえば、アルゴリズム1は、このホワイトペーパーで示した設計連続体のポイントルックアップ操作のこのような一般化されたアルゴリズムを示しています。